|
 |
 |
디지털 인문학: 인공지능 시대의 인문학 활동
기획연재 [K-이야기 속으로] - 김현 한국학중앙연구원 명예교수
|
1. ‘디지털 인문학’이란? 디지털 인문학(Digital Humanities)이란 디지털로 표현하고 디지털로 소통하는 이 시대에 인문 지식이 더욱 의미 있게 탐구되고 가치 있게 활용되도록 하려는 노력이다.
2008년 미국의 인문학재단(National Endowment for Humanities)이 디지털 인문학 지원단(Office of Digital Humanities)을 설치하고 각 대학의 디지털 인문학 연구에 대한 지원을 강화하면서, 디지털 인문학은 미국뿐 아니라 세계 대학의 새로운 관심사로 부상하였다.
우리나라에서도 인문학 연구와 교육의 새로운 활로를 모색하고자 하는 인문계 연구자들이 2015년에 ‘한국 디지털 인문학 협의회’를 결성하고, 디지털 사회 한국에서 인문학의 기능을 제고하는 노력을 기울여 오고 있다.
‘디지털 인문학’이라는 말이 학계와 교육계의 새로운 화두로 떠오르기 전에도 인문 분야의 연구 자료를 데이터베이스로 구축하여 학자들의 연구의 편의를 돕는다든지, 전자책을 만들어서 교육 교재로 활용하는 일이 적잖게 이루어져 왔다.
필자가 우리나라의 대표적인 역사 기록 『조선왕조실록』을 디지털 데이터베이스로 편찬하고 CD-ROM으로 간행한 것은 30년 전인 1995년의 일이다. ‘인문학 자료 전산화’라고 했던 이러한 유의 일들과 오늘날 ‘디지털 인문학’이라고 부르는 것 사이에는 어떠한 차이가 있을까?
2. 자료 전산화 시절의 ‘디지털’과 ‘인문학’
‘인문학 자료 전산화’ 단계의 ‘디지털’은 ‘책을 읽고 글을 쓰는’ 전통적인 인문학 활동의 편의성을 증진하는 역할을 하였다.
그 시절의 디지털은 인문학 연구와 교육에 필요한 읽을거리를 찾고 정리해 주는 보조적인 역할을 할 뿐이었고, 그 자료를 읽고 해석하고 정리하는 활동은 오로지 사고력을 갖춘 인간만이 해낼 수 있는 것으로 간주되었다.
이러한 사고에 길들여진 사람은 디지털의 기술로 수행하는 일과 인간적 사고를 기반으로 이루어지는 일이 마치 전혀 다른 차원의 일인 것처럼 생각하기도 한다.
사실상 ‘인문학 자료 전산화’ 시절에는 수많은 인문학 연구자 교육자들이 ‘학술 정보 데이터베이스’와 같은 디지털 저작물에 크게 의존하면서도, 그것을 편찬하는 행위는 그저 기술적인 일이며, ‘인문학 활동’은 그것을 활용해서 글을 쓰거나 강의를 하는 자신들의 행위라고만 생각했다.
그런데 이런 식의 사고가 “거대 언어 모델(Large Language Mode, LLMl)”이라는 인공지능의 등장으로 큰 혼란을 겪고 있다.
컴퓨터의 역할이 인간의 생각을 돕는 자료와 정보의 제공에 멈추지 않고, 스스로 생각해서 결론까지 만들어 내는 듯이 보이며, 심지어는 이어서 탐구해야 할 과제까지 제시하는 등 과도한 친절을 베풀고 있기 때문이다.
선생에게 질문하기보다는 인공지능에게 묻고, 선생이 내주는 과제에 대해 인공지능이 만들어 준 리포트를 제출하는 학생들을 대면하면서, 대학의 인문학 교수들은 심각한 고민에 빠져들고 있다. 인공지능 시대에 인문학은 어디로 가야 하나?
자료 전산화 시절에 ‘디지털’과 ‘인문학’을 이원화했던 사람들은 그 사고의 연장선상에서 ‘인공지능’과 ‘인문학’을 대척적으로 바라본다. 예전에는 ‘디지털’이 인문학자의 하인 역할을 했는데, 이제는 ‘인공지능’이 주인 행세를 하고 인문학자는 할 일을 잃게 되었다고….
이런 식의 사고가 간과하고 있는 사실이 있다. 인문학의 타자로 인식하는 인공지능은 언어로 지식을 만들어온 인문학 활동이 있었기에 만들어질 수 있었다는 점이다.
3. 인공지능 시대의 ‘디지털’과 ‘인문학’
‘인공지능’이 무엇인지를 묻는 어느 철학 교수의 질문에 “불교에서 말하는 업(業)과 같은 것”이라고 답한 적이 있다. 불교에서는 한 인간의 사고, 언어, 행위가 시간과 함께 사라지는 것이 아니라 그 인간의 업(業)으로 남아 윤회전생(輪廻轉生)한다고 한다.
20세기 말부터 인간이 남긴 언어적 행위의 자취가 디지털 데이터로 저장되기 시작했고, 21세기에 들어서면서 그 데이터의 많은 부분이 인터넷을 통해 수집될 수 있게 되었다. 이러한 상황이 오늘날의 거대 언어 모델의 탄생을 가능하게 한 배경이 된 것이다.
이러한 정황에서 이야기한다면, 인류의 지성사에서 언어로써 지식을 체계화하는 역할을 주도해 온 인문학은 바로 인공지능의 모태라고 해도 과언이 아닐 것이다. 과거의 인문학이 인공지능의 탄생에 기여했다면, 미래 인문학의 역할은 그 인공지능을 인간에게 더 큰 도움을 주는 ‘인문 지식 활동의 동반자’로 성장시키는 일이다.
며칠 전에 만난 역사학 교수는 인공지능에 의해 퇴출 위기에 있는 인문학이 이제 어떤 역할을 해야 하느냐고 물었다. 나는 “인공지능을 가르치는 인문학”이라고 답했다.
챗지피티(ChatGPT)를 비롯해 클로드(Claude), 구글(Google) 검색창에 적용된 ‘AI 개요(Overview)’ 등 ‘거대 언어 모델(Large Language Model, LLM)’ 인공지능은 어느 한국인에게 견주어도 크게 손색이 없을 정도의 한국어 구사력을 보여 우리를 놀라게 하고 있다.
그렇지만 말 잘하는 인공지능이 그 말을 배우는 과정에서 터득한 지식은 엄밀성을 중시하는 학술적 교육의 소산이 아니기 때문에 부정확하고 모호한 부분이 혼재되어 있다. 당연히 ‘교육적 역할’을 맡기기에는 부족하다.
인공지능의 언어능력과 추리능력, 잡다한 정보력을 ‘정확한 문맥의 지식 정보 데이터’로 통제하고 검증할 수 있을 때 비로소 인공지능은 신뢰할 수 있는 교사의 역할을 할 수 있다.
4. 디지털 인문학: 인공지능 시대의 인문학 활동
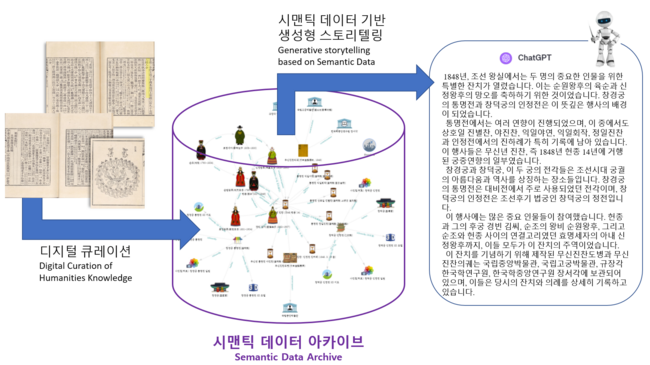
인공지능에 정보를 전달할 때 데이터의 형식은 인공지능의 성능과 능력에 상당한 영향을 미친다. 복잡한 사건과 인물의 관계 속에서 특별한 맥락을 탐색해 내거나 그 맥락을 사람들이 쉽게 이해할 수 있는 자연어 내러티브로 변환하는 작업 등을 인공지능에게 요구할 때, 구조화된 데이터를 제공하는 것은 자연어 텍스트 데이터를 제공하는 것에 비해 훨씬 더 우수한 결과를 얻을 수 있다.
필자가 최근 수년간 디지털 인문학을 공부한 젊은 연구자들과 함께 집중해 온 일은 한국의 전통문화와 한문 고전에 관한 지식을 구조적인 데이터로 전환하여 집적한 인문 지식 데이터 아카이브를 만드는 일이다.
고립된 정보의 조각을 모아놓는 것이 아니라, 그 조각과 조각 사이의 관계를 체계적으로 정리해서 지식의 문맥과 의미를 찾을 수 있게 하는 이 아카이브를 ‘시맨틱 데이터 아카이브(Semantic Data Archive)’라고 한다.
시맨틱 데이터 아카이브 안에 들어 있는 지식 정보 데이터가 RAG(Retrieval-Augmented Generation: LLM이 응답을 생성하기 전에 외부의 신뢰할 수 있는 지식 베이스를 참조하도록 하는 프로세스) 등의 기술적 장치를 통해 거대 언어 모델의 인공지능과 결합하게 되면, 인공지능의 말재주가 부정확한 장광설로 흐르지 않고 검증된 지식을 정확하게 표현할 수 있는 방향으로 개선될 수 있다.
인공지능의 응용이 이런 방향으로 고도화되면, 비로소 우리의 역사와 고전에 대한 정확한 지식을 가르치는 교사의 역할을 맡길 수도 있고, 한국의 문화에 대한 올바른 인식을 여러 나라 언어로 전파하는 커뮤니케이터의 역할도 맡길 수 있게 된다.
아날로그 시절에는 교사가 직접 학생들을 대면하여 읽고, 생각하고, 쓰는 문식(文識)의 방법을 가르쳤고, 그것이 그 시대의 인문학이었다. 인공지능에게 묻고, 인공지능에게 배우는 것을 외면할 수 없는 인공지능 시대의 인문학은 바로 그 미래 세대들이 ‘인공지능’을 매개로 올바른 인문학 공부를 할 수 있도록 하는 노력일 것이다.
인공지능은 대학에서 인문학을 퇴출시키는 것이 아니라, 더 높은 강도로 인문학 활동이 강화될 것을 요청하고 있다. 다만 그 인문학의 방법이 과거에 해 오던 행태에 머물지 않고, 인공지능과 동행할 수 있는 새로운 모습이어야 하는 것일 뿐. 디지털 인문학은 새로운 분과 학문이 아니라, 모든 전통적인 인문학이 인공지능의 시대에 새롭게 갈아입어야 할 옷과 같은 것이다.
특별기고 김 현 한국학중앙연구원 한국학대학원 인문정보학 전공 명예교수 전통문화연구회 회장 저작권자 ⓒ 비전성남, 무단전재 및 재배포금지
|
많이 본 기사
|