|
 |
 |
|
언어를 사랑하고 연구하는 저자는 요즘 불편한 것이 있다. TV 방송을 볼 때마다 귀에 거슬리는 표현이 계속 들리기 때문이다. 바로 이유를 나타내는 표현 ‘-아/어서’의 잘못된 사용이다. 다른 이유의 문법과 다르게 ‘-아/어서’는 시간을 함께 병기할 수 없다. 예를 들면 ‘어제 운동을 열심히 했어서 오늘 몸이 피곤하네요’처럼 과거 시제와 함께 말하면 비문법적인 문장이 된다. ‘열심히 했어서’가 아니라 ‘열심히 해서’로 말해야 정확한 문장이 된다.
이러한 비문들이 TV 방송이나 인터넷 곳곳에서 심심찮게 보일 뿐만 아니라 시간이 갈수록 증가하는 현상을 보인다. 물론 엄연한 규정을 지켜야 하는 학교 문법과 현실 속 언어 양상이 엄격하게 일치되어야 한다고 주장하는 바는 아니다. 방송에서 이러한 비문을 사용하지 말아야 한다고 목소리 크게 낼 일도 아니다. 왜냐하면 언어는 시간의 흐름 속에서 변화되고 발전하는 우리 인간의 사고 능력을 반영하기 때문이다.
조심스럽게 추측해 본다면 인터넷의 보급으로 짧은 텍스트, 짧은 문장을 생성해야 하는 상황 속에서 시간과 같은 정황을 구구절절 언급할 수 없어서 하나의 문장 안에서 한꺼번에 시간의 의미를 드러내고자 하는 무의식적인 행동의 결과일 수 있다. 이러한 한국어 화자의 습관이 결국 시간이 흘러 문법을 바꾸고, 사전을 변하게 할 것이다.
시선을 바꾸어 인공지능의 이야기를 해 보면 요즘 언어 모델이 빠르게 발전하고 있다. 단순히 번역 기능을 뛰어넘어 다음에 나올 단어 또는 문장까지 정확하게 추론할 수 있을 정도로 발전했다. 인간의 두뇌를 본떠 구축된 신경망 모델은 학습 능력까지 갖춰 이제 인간의 지능을 넘보게 되었다.
우리가 매일 접하는 핸드폰, 컴퓨터에 이미 들어와 있으며 이제는 인공지능을 탑재한 피지컬 AI가 각광을 받고 있다. 집마다 사람들의 고민과 노동을 해결해 줄 로봇이 한 대씩은 있을 날도 멀지 않았다.
인공지능 속 언어 모델이 갈수록 발전하고 정확해지고 있지만 유난히 한국어 언어 모델의 발전 속도는 다른 언어와 다르게 기대에 못 미친다. 연구 인력과 투자 및 지원 등에 있어 부족함이 없지만 한국어의 특성이 모델 구축에 많은 어려움을 제공하고 있다.
단어만 몇 개를 나열해도 의사소통이 어렵지 않은 언어인 영어는 보통 논리적인 언어라 하고 상대방의 마음과 맥락이 무엇보다 중요한, 그래서 외국인들이 배우기에도 쉽지 않은 언어인 한국어는 보통 감정적인 언어라고들 한다. 외국인들이 공부할 때 모르는 표현을 한국 사람들에게 물어보면 사람마다 그 의미를 다르게 설명할 정도이니 인공지능도 한국어를 학습하기 매우 까다로울 것이다.
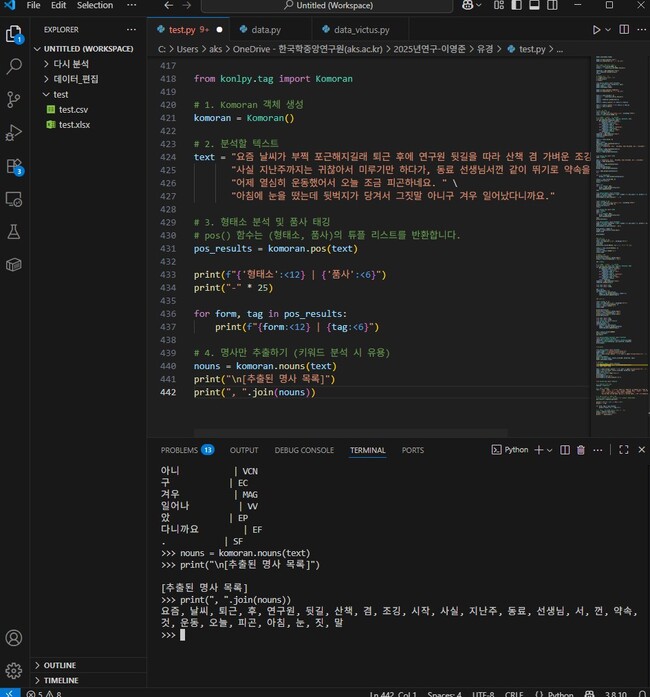
인공지능에 사용되는 계산법과 함수 등이 매우 어렵지만 그 기반은 빈도수이다. 단어와 문법이 어떤 텍스트에서 몇 번 사용되었는지 이 기본적인 빈도수를 기반으로 복잡한 함수를 써서 추론 과정을 심화시킨다. 따라서 텍스트와 문장들을 단어 또는 개별 문법으로 잘게 쪼개는 과정이 필수적이다. 그러나 한국어에서는 그 경계가 모호한 경우가 많다. 일단 띄어쓰기부터 상황에 따라 너무 가변적이어서 한국어 어문 규정 내에서도 여러 예외를 두고 있을 정도이다.
이렇게 단어 또는 개별 문법 표현을 구분하는 과정을 형태소 분석이라고 부르며 인공지능 개발의 첫 단계가 된다. 이전에는 단어 형태의 일치 여부를 기준으로 분석을 하였는데 이러한 방법은 형태소 분석기 내의 사전이 모든 단어를 담고 있어야 했고, 여러 의미를 품고 있는 다의어는 처리가 어려웠다. 물론 분석에 소요되는 시간도 오래 걸리고 많은 메모리가 필요하여 일반 컴퓨터로는 감당이 되지 않을 정도였다.
현재는 형태소 분석 방법도 고도화되어서 단어를 문자 단위로 쪼개어 빠르고 효율적으로 처리하고 있다. 사전에 없는 단어라도 분석이 가능해진 것이다. 그럼에도 더 정밀한 언어 모델을 만들기 위해서는 조사나 접사, 어미들이 발달한 교착어로서의 한국어에 대한 고민이 많이 필요해 보인다.
앞서 언급한 ‘어제 운동을 열심히 했어서 오늘 몸이 피곤하네요’의 문장을 인공지능이 우연히 조우한다면 ‘하’, ‘-았/었’, ‘-아/어서’로 형태소로 분석하고 이해할 것이다. 빈도수에 기반하기 때문에 아직은 그렇지 않겠지만 시간이 흘러 ‘했어서’와 같은 문장이 더 많아진다면 한국어 언어 모델을 탑재한 로봇도 똑같이 이처럼 말하게 될 것이다.
요즘은 매체의 발전으로 한국어가 실시간으로 보급되고, 표준어가 확대되었지만 아직도 지역마다 방언의 특성이 남아 있다. 경기도의 예를 들자면 ‘오’를 ‘우’로 발음하는 경우가 흔한데 ‘먹구 싶다’, ‘했다구요’, ‘삼춘’이라고 말하는 경우가 그러하다.
언어는 변화되고 발전하는 우리 인간의 사고 능력을 반영하고, 또 인공지능이 탑재된 로봇도 이를 따라할 것이다. 이제 곧 집집마다 있게 될 우리 로봇이 옆집 아주머니하고 이야기하듯이 이렇게 구수하고 편하게 대화하게 될 날도 멀지 않았다.
특별기고 이영준 한국학중앙연구원 한국학대학원 책임연구원
한국학중앙연구원(https://www.aks.ac.kr) 성남시 분당구 하오개로 323 소재 저작권자 ⓒ 비전성남, 무단전재 및 재배포금지
|
많이 본 기사
|